チームとして行う障害訓練のススメ(Disaster in recovery training) (インシデント管理)
ローンチしたサービスをチームとして運用していく中で、必ず直面するであろう「障害」への向き合い方についての事例を説明します。
■ 前提
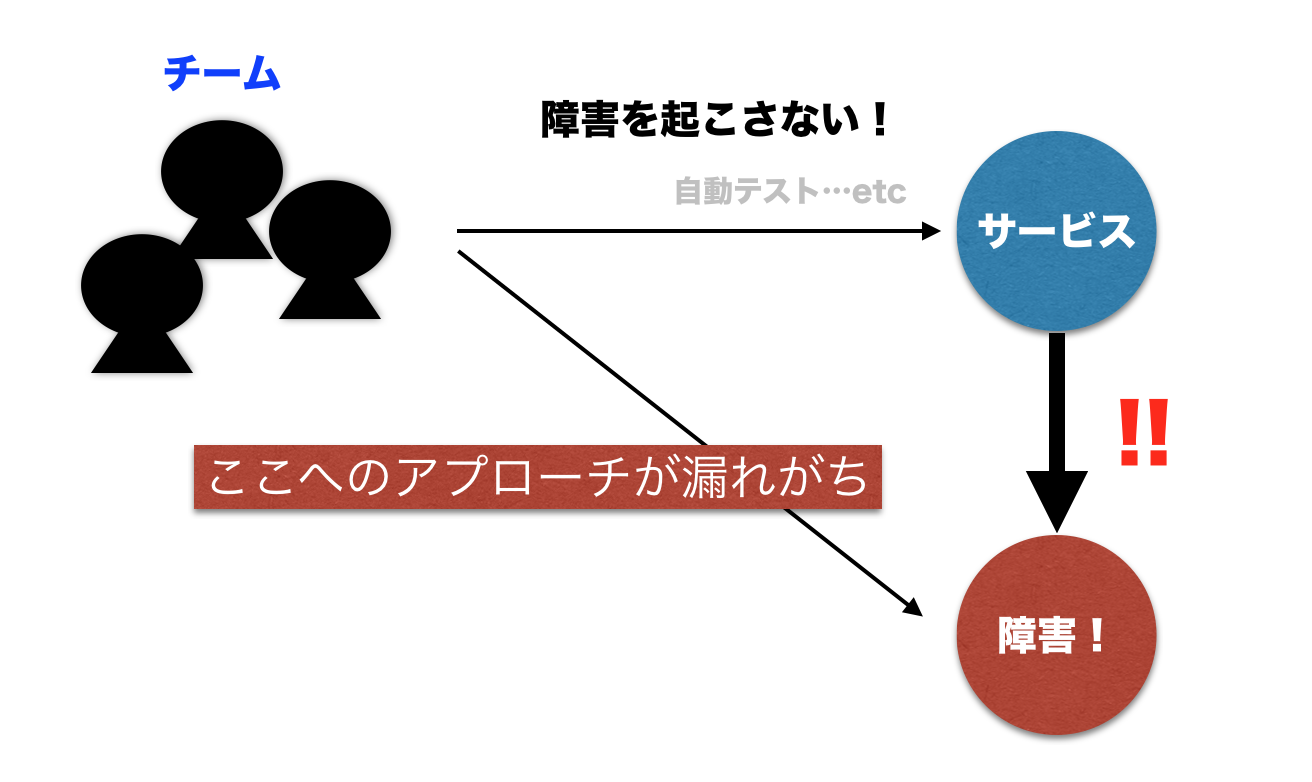
ローンチしたサービスを保守運用していく上で、インシデント管理は非常に重要です。 インシデントばかりでサービスの稼働率が低いと自然とユーザも離れていってしまいます。 ここでは、障害を起こさないためのインシデント管理ではなく、障害を早く復旧する方法としての「障害管理」の方法を記載したいと思います。
■ 障害訓練について
障害訓練とは端的に言うと
「インシデント対応者以外の人が「障害シナリオ」をもとに意図的にシステムに障害を起こし、対応者がいかに早く障害を復旧させるかのプロセスを学習するプログラム」です。
目的や学習するべき部分は下記になると考えられます。
原因追求のアプローチ改善
- 障害起因に対して、障害原因の箇所の「追求」から「発見」に至るまでのアプローチ方法を改善することで、全体を通した復旧までの時間を短縮する。
復旧までのアプローチ改善
- 障害原因の「発見」したら、いかにその障害を早く「復旧」させるかのアプローチの仕方を改善することで全体を通した復旧までの時間を短縮する。
報連相の粒度・質・タイミングの改善
- 報告をエスカレーションする必要がある場合は、どんな報告・連絡・相談をするべきかをある程度標準化することで全体を通した復旧までの時間を短縮する。
■ 障害訓練の実施の流れ
▼ 障害訓練の流れ
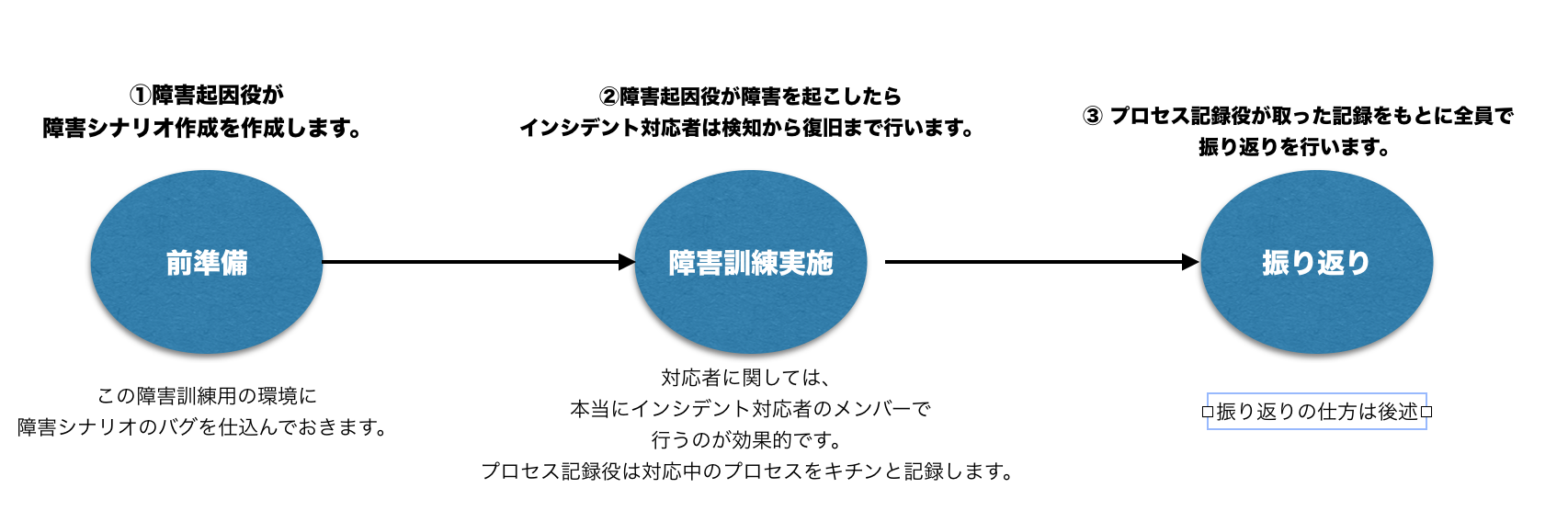
補足として障害訓練における目標復旧時間を定めて、その時間以内の復旧を目指すようにするとさらに緊張感が生まれると思います。
▼ 下記に障害訓練を実施するにあたる役割を記載します。
| 役割 | 説明 |
|---|---|
| 障害起因役 | 障害起因を起こす及び障害シナリオを作成する人 |
| インシデント対応者 | 障害起因に対して、障害原因を探し復旧させる。(チーム) |
| プロセス記録役 | 障害訓練の最中にインシデント対応者がどういった行動を行なっていたかを詳細に記録する人 |
■ プロセス記録役は何を記録するのか。
障害訓練は、プロセス記録役が非常に重要です。ここで記録したプロセスをもとにどこを改善すればよいかが見えてきます。 ここでは障害対応中の「会話のプロセス」及び「アクションのプロセス」を記録することをオススメしています。 例えば、下記のほうな形です。
| 人 | 時間 | プロセス |
|---|---|---|
| Aさん | 10/28 10:00 | 〇〇より障害を検知しました。私のほうで調査に入ります。 |
| Bさん(リーダー) | 10/28 10:10 | 承知しました。対応お願いします。 |
| 監視ツール | 10/28 10:20 | 障害対象ではないアプリケーションでエラー通知 |
| Bさん | 10/28 11:00 | Aさん、状況どうでしょうか? |
| Aさん | 10/28/11:20 | 障害原因を突き止められずに試行錯誤していた結果、他アプリケーションにも影響がでてしましました。 |
| Cさん | 10/28 11:00 | Aさん、私のほうで15分前に障害原因を特定し、復旧作業に入っています。 |
上記のようなプロセスを取ることで、下記の問題点が可視化されます。
★Aさん、Cさんによる単独的な行動が可視化され報連相の粒度・質・タイミングの改善ポイントが見える。
上記の場合は、まずインシデント対応者のリーダーであるBさんが状況を詳細に把握して体制を組むべきと考えます。それから人的リソースがどのくらいいるかを判断し適切にインシデント対応者をアサイン、原因追求の分担を行うような流れがよいと考えます。
■ 振り返りについて
障害訓練が終わったら、関係者全員で振り返りを行うことを推奨しています。その場で行うことは下記です。
① 「会話のプロセス」及び「アクションのプロセス」の読み合わせをし、改善点を全員で出し合う。 ② 復旧プロセスについての技術点議論を行う。障害起因役を中心にどうやったら早く復旧できる道筋があったかをインシデント対応者と議論します。
■まとめ
上記に書いたとおり、この取り組みをだいたい四半期に1度行うと形骸化せずに上にも書きましたが下記のような成果ができるとおもいます。 - 原因追求のアプローチ改善 - 復旧までのアプローチ改善 - 報連相の粒度・質・タイミングの改善
以上です。皆さんもぜひ障害訓練を行なってみてください。
属人化という人的SPOF(単一障害点)について
■ 前提
下記に基本的な用語の説明を記載します。 「属人化」 特定の業務について特定の人しか行えない。やり方が展開されていない。つまりその人しかその業務を遂行することができない状態
「SPOF」 単一障害点。つまり、ひとつのコンポーネントで障害をきたすとシステム全体のコンポーネントで異常をきたしてしまう。
■ 属人化の問題点
下記に属人化することでの問題点を記載します。
- 属人化タスクがあるチームのパフォーマンスは、開発全体の進捗低下につながる。ゆくゆくは秘伝のタレへ.....
- 属人化されたタスクからアウトプットされた成果物に問題(バグ)が起きたときに他の開発者が対応できない。人的SPOFになりやすい。

■ 属人化になるまでの流れ
下記に属人化になるまでの流れを記載します。主に下記の2つがあると考えます。
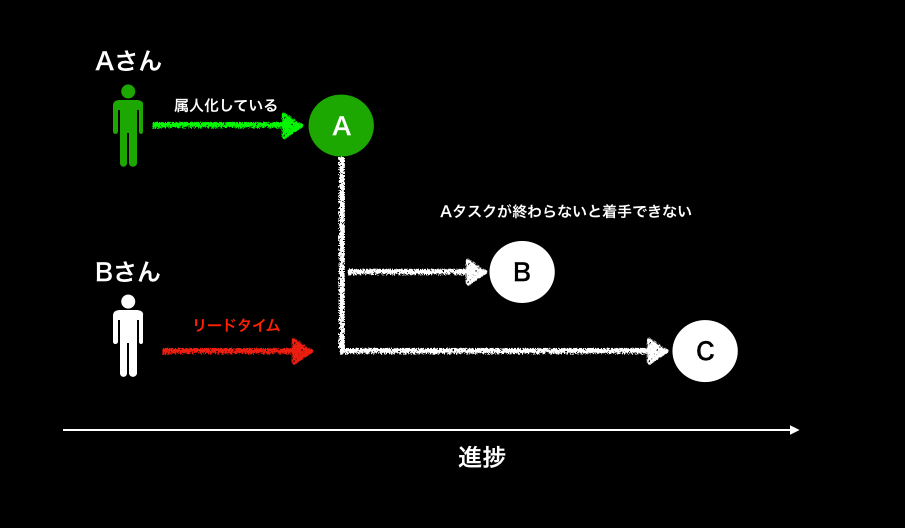
① 大規模プロジェクトのようなスピード感が求められている開発現場の場合
- 下記図にあるようにどうしても「類似タスク」があると前同じようなタスクを行なった人のほうがスピード感が高いためPBIを振りがちです。そうすると下記でいう「Aタスク」が属人化しやすいです。※ ex. サーバ構築作業

② 新しい開発者が入ってきた際にドキュメントなどがなく横展開ができていない場合
- 2,3人の少人数チームの中で、少人数ゆえに口頭などでコミュニケーションが活発な仕事現場において、新しく2,3人の開発者が入ってきたときに「ドキュメント」や、サーバ構築であれば「サーバ管理ツール(Chef,Ansible)の設定ファイル」がないなどで、結果としてAタスクが属人化してBさんがAタスクを行うことへのハードルが上がります。

■ 今後、属人化を起こさないための業務プロセス
下記に今後チーム内で属人化を起こさないために必要なプロセスを記載します。

参考資料
https://developers.eure.jp/tech-management/advent-calender-17/ http://at-grandpa.hatenablog.jp/entry/2017/07/25/082252
Slack駆動を活かしたMonitoringについて
www.slideshare.net
上記スライドで説明しているSlackを活かしたSystemMonitoringについて記載します。 テーマとしては下記になります。
- Monitoringについて
- Slackを使ったDevopsの部分について
■ ブラックボックスモニタリングとホワイトボックスモニタについて
はじめにシステムのMonitoringには2種類あると思っています。
- ブラックボックスモニタリング
- ホワイトボックスモニタリング
の2つです。
ブラックボックスモニタリングとは、あるシステムを外部(例:ユーザ)からの動作、振る舞い、インターフェースの状態を見ます。
ホワイトボックスモニタリングとは、あるシステムの内部の状態を見ます。いわゆるコンピュータリソースです。
この2つがあることを認識して効果的にモニタリングをするべきと考えます。

そしてこの2つのモニタリングの中でどっちを優先するかについては、「 ブラックボックスモニタリング」を重要視するべきと考えます。 それは、サービスを運用する上でユーザに影響があるかないかが一番重要なためです。
■ モニタリングツールについて
上記でモニタリングには、ブラックボックスとホワイトボックスの2種類のモニタリング手法があるといいましたがここではそれぞれどういったモニタリングツールが有効かを記載します。
ブラックボックスモニタリングツールについて
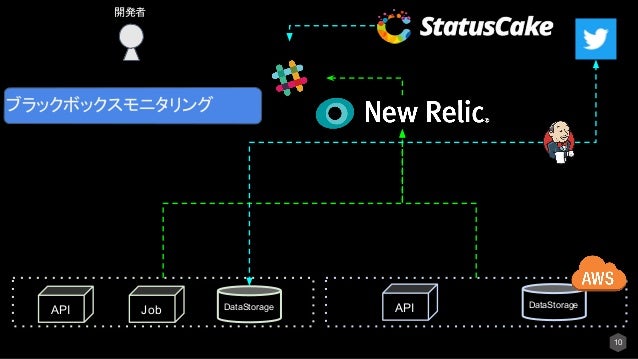
※図はAPIをモニタリングしている例です。
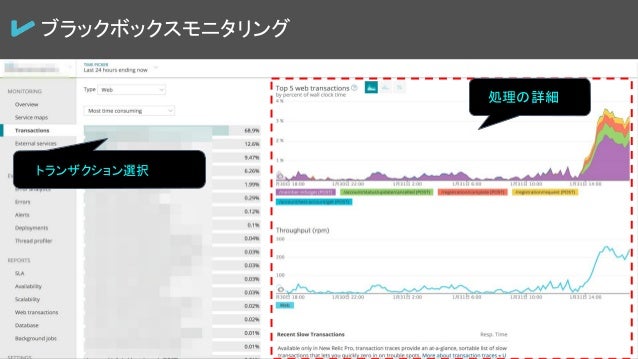
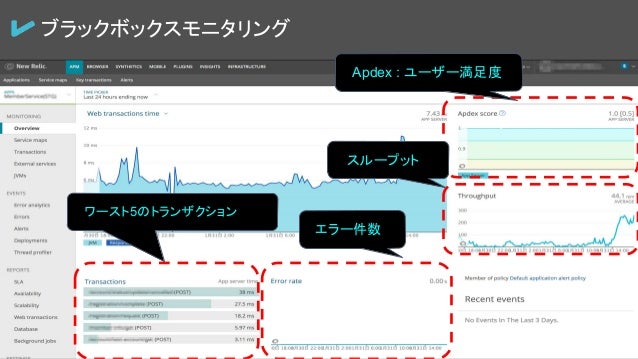
モニタリングツール① NewRelic APM
NewRelicは優れたモニタリングツールであり様々なサービス監視のノウハウを持っています。

今回、採用しているにはAPIのApplicationMetricsである、NewRelic APMです。
トランザクションのごとにスループットやエラー件数などを出してくれます。
モニタリングツール② StatusCake
StatusCakeはいわゆる死活監視の役割をしています。特定のURLに対して数分感覚でリクエストを送り続けサイトがダウンしているかどうかを監視できます。
モニタリングツール③ Twitter
再度にTwitterになります。こちらは精度的にはそこまで高くはありませんが、[サービス名] [できない] などの検索で引っかかったものに関してStatusCakeでURL監視を即時に飛ばしアラートを飛ばすなどをしています。ここらへんは機械学習などを置きこんで作り上げればもう少しよい精度のものができるかもしれません。
ホワイトボックスモニタリングツールについて
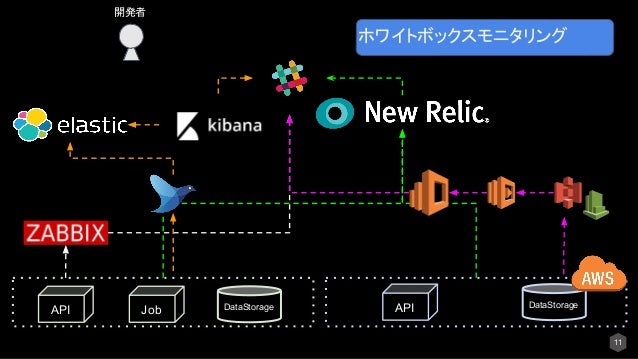
モニタリングツール④ Zabbix CloudWatch(AWS) NewRelic Infrastructure https://aws.amazon.com/jp/cloudwatch/ https://www.zabbix.com/jp/ https://newrelic.com
上記であげたものは、すべてコンピュータリソースの監視で利用しています。詳しい説明は省きます。
モニタリングツール⑤ Elastic https://www.elastic.co/jp/products/elasticsearch
最後にログ収集基盤に関しては、Elasticサービスが有名です。 自チームではログコレクタとして、fluentdを採用しElasticSearchに転送→kibanaでビジュアライズして可視化しています。 実際のサーバに入らなくても、エラーログなどの情報がGUI上で誰でも見れることはとても重要です。
■ Slack駆動について
最後にSystemMonitoringの運用(Devops)について記載します。
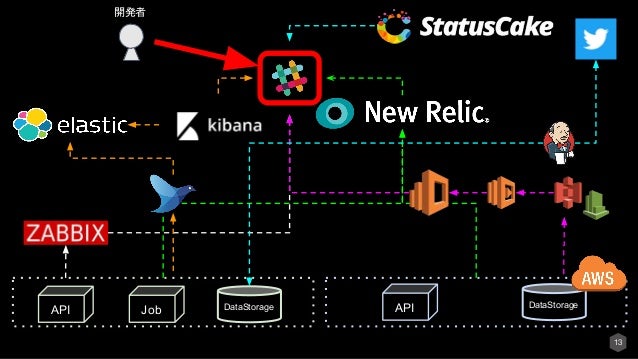
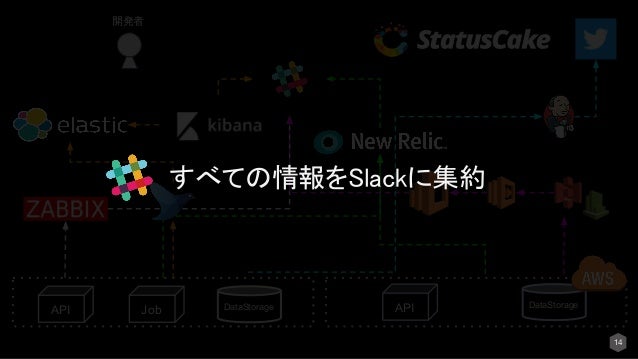
上記で説明したような多数のモニタリングツールを利用しているとその場面ごとに開発者がツールにアクセスするのは大変です。
なので図のあるようにSlackに集約します。
すると開発者が情報を取りに行かなくても、通知してくれるのでインシデントの観点からとても有効です。
※下記がインシデントの観点から実際にあった効果です。

また、通知だけでなく例えば検知したタイミングでプロダクトをロールバックしたい等があればそれもプロダクトとSlackをつなげてしまえばSlack上から障害対応も可能になっていきます。同様にモニタリングツールとSlackをつなげてしまえばとても幅は広がります。
■ まとめ
Monitoringについて
- ブラックボックスモニタリングとホワイトボックスモニタリングがある。
Slackを使ったDevopsの部分について
- モニタリングツール、プロダクトのinputとoutputをSlackにつなげることでインシデント管理、障害対応はとてもスピーディーに有効に働く。
VSM (Value Stream Mapping)の改善プロセスの悩みを「カイゼン・ジャーニー」を読んで解決した。
背景
常日頃から、VSM (Value Stream Mapping)を使った改善を続けていますが、改善プロセス(どうやって改善していくか)の方法にずっと悩んでいた。
そんな中、最近クラウドエナジャイズ経由でコミュニティーにも参加しだした、「カイゼン・ジャーニー」という本を読みました。
CrowdEnergize(クラウドエナジャイズ) — 行動を通じて、人を応援する
この本の中で特に自身の状況とマッチして解決したのがVSM (Value Stream Mapping)について述べられているものになります。
本題
普段、VSM (Value Stream Mapping)を記載して「ムダ」を可視化した後、私の場合は
- カテゴリー分けをする。
- カテゴリーごとにどのくらいリードタイム、プロセスタイムがかかっているかを計算
- どこを改善していくか検討する。
といった方法を取っていました。

これでも特に間違えではないとは思いましたが、カイゼンしていくのに「ポリシー」みたいなものがないかを探していた。
そんなとき「カイゼン・ジャーニー」という本に出会いました。 「カイゼン・ジャーニー」ではリードタイムを削減するポイントとして下記を提示していました。
ポイント① 待ち時間が長く、ボトルネックとなっているプロセス付近
とある。VSMには待ち時間といった観点では2つあると思っており
- プロセスタイムの中で待ち時間(WT)
- リードタイムの待ち時間(プロセス間での待ち時間)
の2つである。どっちかというとリードタイムの待ち時間の待ち時間のほうが多くなる傾向が高い。なので実行時間(PT)を短縮するよりも上記のような待ち時間を削減したほうがよい。
ポイント② 手戻りが発生していて、その割合が発生しているプロセス
と次にある。例としてあげているのを一部引用させていただくとプロセスの最終段階でテストをすると不具合があったときにそのプロセスがすべて手戻りになってしまうのでTDDを導入する等をしたほうがプロセスとしてスムーズに行くと言った形である。
そして、私自身がほしいと思っていた
カイゼンしていくのに「ポリシー」みたいなものがないかを探していた。
といった面だとこの章に書いてあったコラムとして上がっていたECRSの原則がとても参考になった。
ECRSの原則とは?
ECRSの原則とは、業務改善方法の4原則でVSMに当てはめると
- Eliminate(排除): そのプロセスは本当に必要な業務かどうか。
- Combine(結合) : 作業分担をしずぎて、逆に待ち時間のムダを発生させていないか。
- Rearrange(交換 ) : プロセスの順番を入れ替えることで効率化を測れないか。
- Simplify(簡素化): 作業を簡易化することで効率化できないか。
の4つの頭文字をとっています。 一般的に1→2→3→4の順番でおこなうべきとしています。
- プロセス自体を(排除)すれば作業自体がなくなるので大きな改善(リードタイムの削減)につながります。
- また、作業分担を見直しプロセスを(結合)することで削減できるものも多いとおもいます。
(交換)に関しては、
例としてあげているのを一部引用させていただくとプロセスの最終段階でテストをすると不具合があったときにそのプロセスがすべて手戻りになってしまうのでTDDを導入する等をしたほうがプロセスとしてスムーズに行くと言った形である。 にあるような例が当てはまると思います。
最後に(簡素化)に関しては、複雑なことをせずに作業を簡単にする。また作業を標準化するなどで横展開できるようにすることでも良いと思いました。
ECRSの原則は本書(カイゼン・ジャーニー)ではじめて知ったので非常に助かりしました。
上記で記述したようなことをもとに改善を進めていきたいと思います。
スクラムにおけるプロダクトバックログアイテム(PBI)の優先順位づけについて考えてみた ~ CD3を用いて考察 ~
■ 前提
スクラムのフレームワークではプロダクトバックログを「ビジネス価値」によって優先順位付けします。しかし「ビジネス価値」をどのように計算するかについては、ほとんど指標はありません。 そこで、経済性で優先順位付けをするフレームワーク(Cost of Delay Divided by Duration)を適応します。
■ CD3 (Cost of Delay Divided by Duration)について
プロダクトバックログアイテムの優先順位付けについて、CD3(Cost of Delay Divided by Duration)といった手法を適応します。
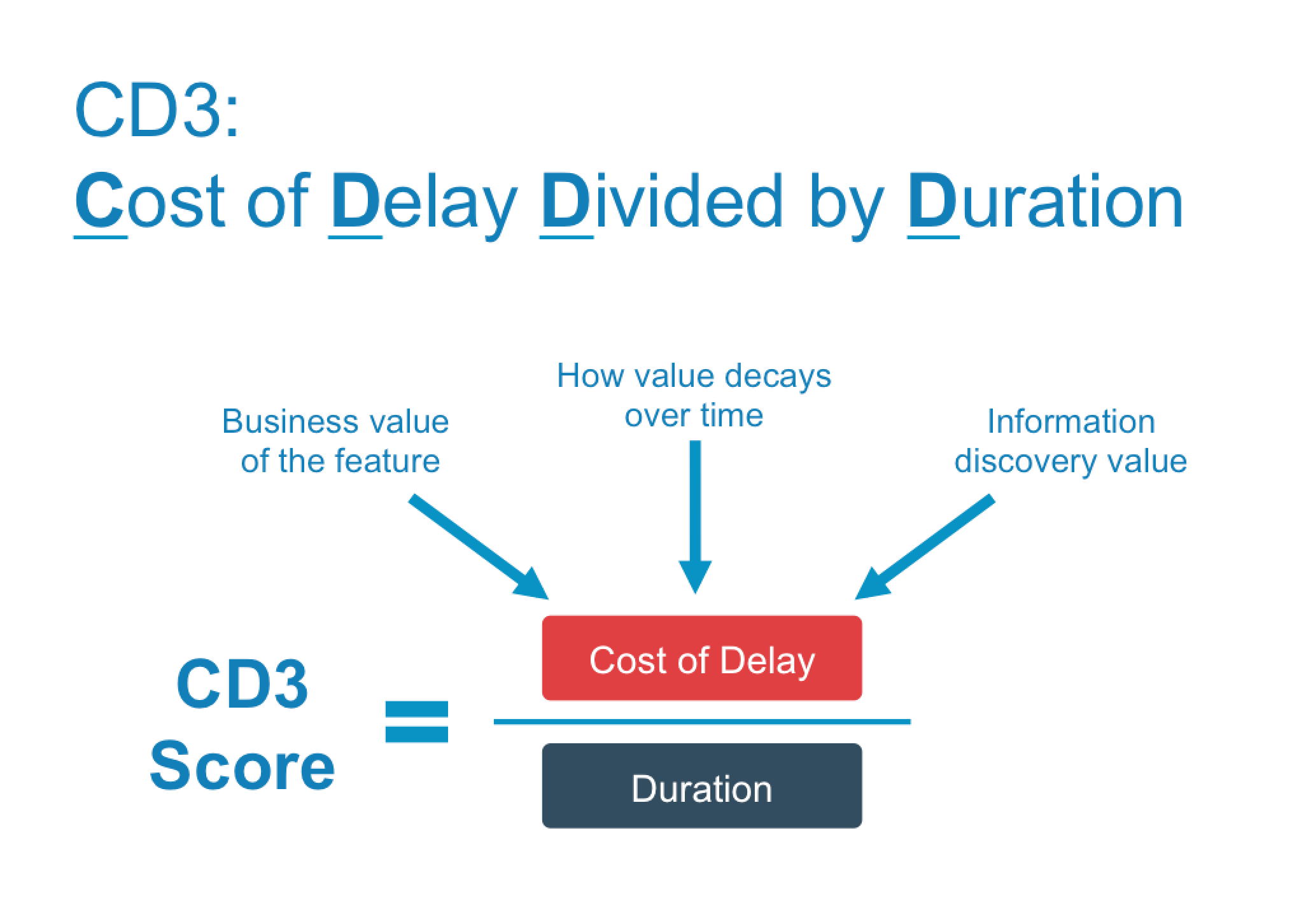
 引用 : Cost of Delay Divided by Duration
引用 : Cost of Delay Divided by Duration
CD3とは、機能の「遅延コスト」を開発からデリバリーまでの見積もり時間で割ったものです。仕事を完了させるのに使える人員とリソースには限界があることを考慮しています。 つまり、ある機能の開発に時間がかかると、それは他の機能を「押しのける」ことになるのです。 引用 : リーンエンタープライズ ―イノベーションを実現する創発的な組織づくり (THE LEAN SERIES)
| 用語 | 意味 |
|---|---|
| Cost of Delay | 遅延コスト(Featureが遅延することでのコスト) |
| Duration | 開発からデリバリーまでの時間 |
| CD3 Score | 遅延コストを開発からデリバリーまでの見積もり時間で割ったもの |
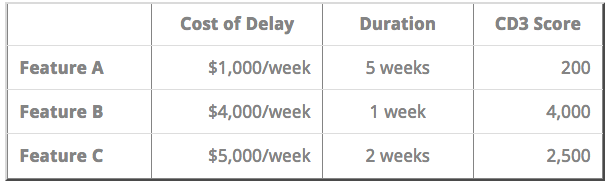
■ 例題
ex. 優先度が最高である、FeatureA, FeatureBがあるとします。 FeatureAは、機能を提供するまで、2週間かかります。納期を守らないと1週間あたり25万円損失します。 FeatureBは、機能を提供するまで、1週間かかります。納期を守らないと1週間あたり10万円損失します。 まとめると下記になります。
| Feature | Cost of Delay | Duration | CD3 Score |
|---|---|---|---|
| FeatureA | 50万円 / week | 2weeks | 25 |
| FeatureB | 10万円 / week | 1week | 10 |
ここで考えられる優先度順位付け方法は3つあると考えられます。
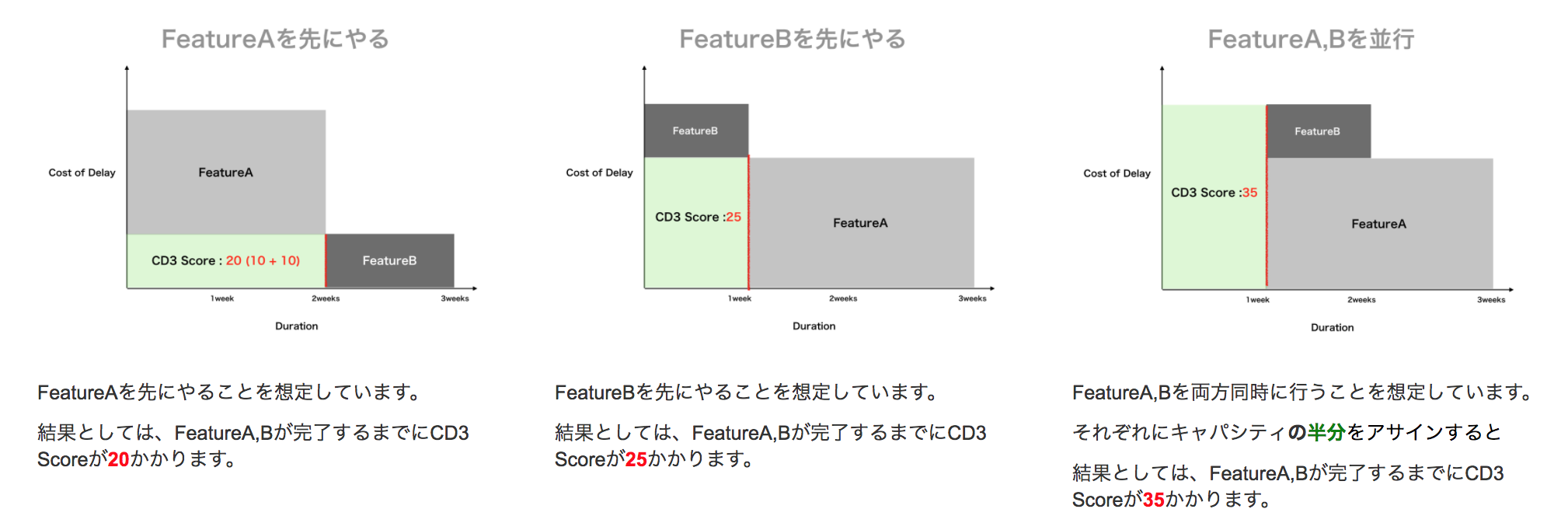
上記、3つの中で、「FeatureAを先にやる」のがCD3的には最適解です。
上記に加えて、各FeatureをDoneさせるPBI(プロダクトバックログアイテム)の優先順位をつけていきます。
例えば、FeatureAをdoneさせるPBIがA,B,CとありFeatureBをdoneさせるPBIがD,E,Fがあるとします。
①まず、各Featureをカテゴリー分けをして、チームの中でどのカテゴリーを優先度高めにするかを決めます。
| カテゴリー | 説明 | 優先順位 |
|---|---|---|
| Business value(ビジネス価値) | 単純な1年間で見込まれる売上額 | 優先順位1位 |
| Technology risk(技術的リスク) | そのリスクが発生したときに損失する額 | 優先順位2位 |
| Advance investment(先行投資) | その投資をした際にどれだけの売上額がみこまれるか。 | 優先順位3位 |
上の例題にCD3を適応し、CD3 Scoreを算出してみたいと思います。
| Feature | Cost of Delay | Duration | CD3 Score | カテゴリー | 優先順位 |
|---|---|---|---|---|---|
| FeatureA | 50万円 / week | 2weeks | 25 | Business value + Advance investment | 1位 |
| FeatureB | 10万円 / week | 1week | 10 | Technology risk | 2位 |
②プロダクトバックログアイテムのレベルの付け方について下記に記載していきます。
各FeatureのCD3のScoreから優先度をつけてしまうと、すべてのPBIが優先度が高いFeatureで独占されてしまうので新しく指標が必要です。 計算式は下記のようなものを想定してみます。
Featureベースのレベル x PBIベースのレベル = 優先度レベル
Featureベースで出したCD3 Scoreをもとにサービスレベル(重み)をつけます。 まず、各FeatureのCost of Delayからサービスレベルを定義します。
| カテゴリー | カテゴリーのレベル(重み) |
|---|---|
| Business value(ビジネス価値) | 3 |
| Technology risk(技術的リスク) | 2 |
| Advance investment(先行投資) | 1 |
| Feature | Cost of Delay | Duration | CD3 Score | カテゴリー | 優先順位 | Featureベースのレベル(カテゴリーのレベルより) |
|---|---|---|---|---|---|---|
| FeatureA | 50万円 / week | 2weeks | 25 | Business value + Advance investment | 1位 | 4(3+1) |
| FeatureB | 10万円 / week | 1week | 10 | Technology risk | 2位 | 2 |
プロダクトバックログアイテムベースにも該当するFeatureをもとにそのFeatureの中でどのくらい重要かを3段階評価でサービスレベルでつけます。
| PBIベースのレベル | 重要度 | 説明 | ex |
|---|---|---|---|
| 3 | 最重要 | このアイテムが完了しないとローンチできない。 | FeatureA:フロント画面作成 |
| 2 | 重要 | このアイテムが完了しなくてもローンチはできるが、非機能要件やSLO,SLAが満たせない | FeatureA:API作成,FeatureB:API作成 |
| 1 | 中 | このアイテムが完了しなくても問題はないが、将来的に必要になったりする運用上少々手間になる。 | FeatureB:フロント画面作成 |
最終的に上のexで出したPBIの優先度は下記になります。
| 優先順位 | PBI | PBIベースのレベル | Feature | Featureベースのレベル | 計算式 | 優先度レベル |
|---|---|---|---|---|---|---|
| 1 | FeatureA:フロント画面作成 | 3 | FeatureA | 3 | 3 x 3 | 9 |
| 2 | FeatureA:API作成 | 3 | FeatureA | 2 | 3 x 2 | 6 |
| 3 | FeatureB:API作成 | 2 | FeatureB | 2 | 2 x 2 | 4 |
| 4 | FeatureB:フロント画面作成 | 2 | FeatureB | 1 | 2 x 1 | 2 |
以上です。
VSM (Value Stream Mapping)を書いたらリリースリードタイムが約200時間も短縮できることがわかった話
用語整理
■ VSM (Value Stream Mapping) とは?
- VSM (Value Stream Mapping) とは、「価値の流れ」を可視化した開発プロセスを可視化するための手法、活動になります。
- 詳しくは、 業務プロセス可視化 : VSM (Value Stream Mapping)を参照してください。
■ リードタイム(LeadTime)とは?
- ここでは、要求が発生してからFeatureを開発→リリースするまでにかかる時間と定義します。
問題提起
- 普段、開発をしていて開発プロセスをあまり意識することは少ないかと思いますが少し客観的的見てみるとリードタイムがものすごいことになっていることがあります。
例を出します。
| No | 説明 | 図 |
|---|---|---|
| 1 | 開発者は会員登録機能を2日で開発しました。テストやコードレビューも通っていてバグもありません。機能要件もすべて満たしていていつリリースしても問題ありません。 |  |
| 2 | しかし、リリースするにはエスカレーション的に担当部署へ承認が必要になってきます。色々な人の予定を見てMTGを設置して開催するまでに2週間かかりました。この時点で2日でユーザに届けられたものが16日後になってしまいます。 |  |
| 3 | ただし、自分の部署だけでなく急に他の部署への確認も必要になったりします。別途調整役をたてて、確認するのに2週間かかりました。この時点で2日でユーザに届けられたものが30日後になってしまいます。 |  |
| 4 | 各所にリリース判断の確認をしてもらってやっとリリースできる状態になりました。しかし、リリースするためのデプロイメントパイプラインが整備されておらず手動でリリースする必要があります。リリース手順を記載したチェックリストを作成しレビューするまでに2日かかりました。 |  |
上記の例でいうと、 2日でリリースできたものが実は32日もかかってしまいました。
【個人的に危険と感じる開発プロセスは下記になります。】
→1個でも当てはまれば、あなたのチームにVSMが必要です!
| No | プロセス |
|---|---|
| 1 | Featureをリリースするまでに開発作業よりも「承認 + 確認」などの調整時間のほうが長い。 |
| 2 | 開発工程の中で手作業が多く、自動化されていない箇所がある。 |
| 3 | Featureの開発は終わっているのに外的要因でリリースができない状態が1週間以上ある |
上記のような危険な開発プロセスのような「ムダ」は組織が大きくなればなるほど増えていくような気がします。このような「ムダ」をなくすためには
まず、開発プロセスを可視化して「ムダ」を洗い出す = VSM (Value Stream Mapping)
となります。
本題 (リードタイムを200時間短縮できることがわかった話)
VSMの作成方法に関しては、 業務プロセス可視化 : VSM (Value Stream Mapping) などを参考にしてください。
まず、VSMを作る大前提の話をするとVSMというのは大事なのは、改善ポイント(=ムダ)を見つけること です。 ※どう改善するかはまた別のレイヤーの話ということです。
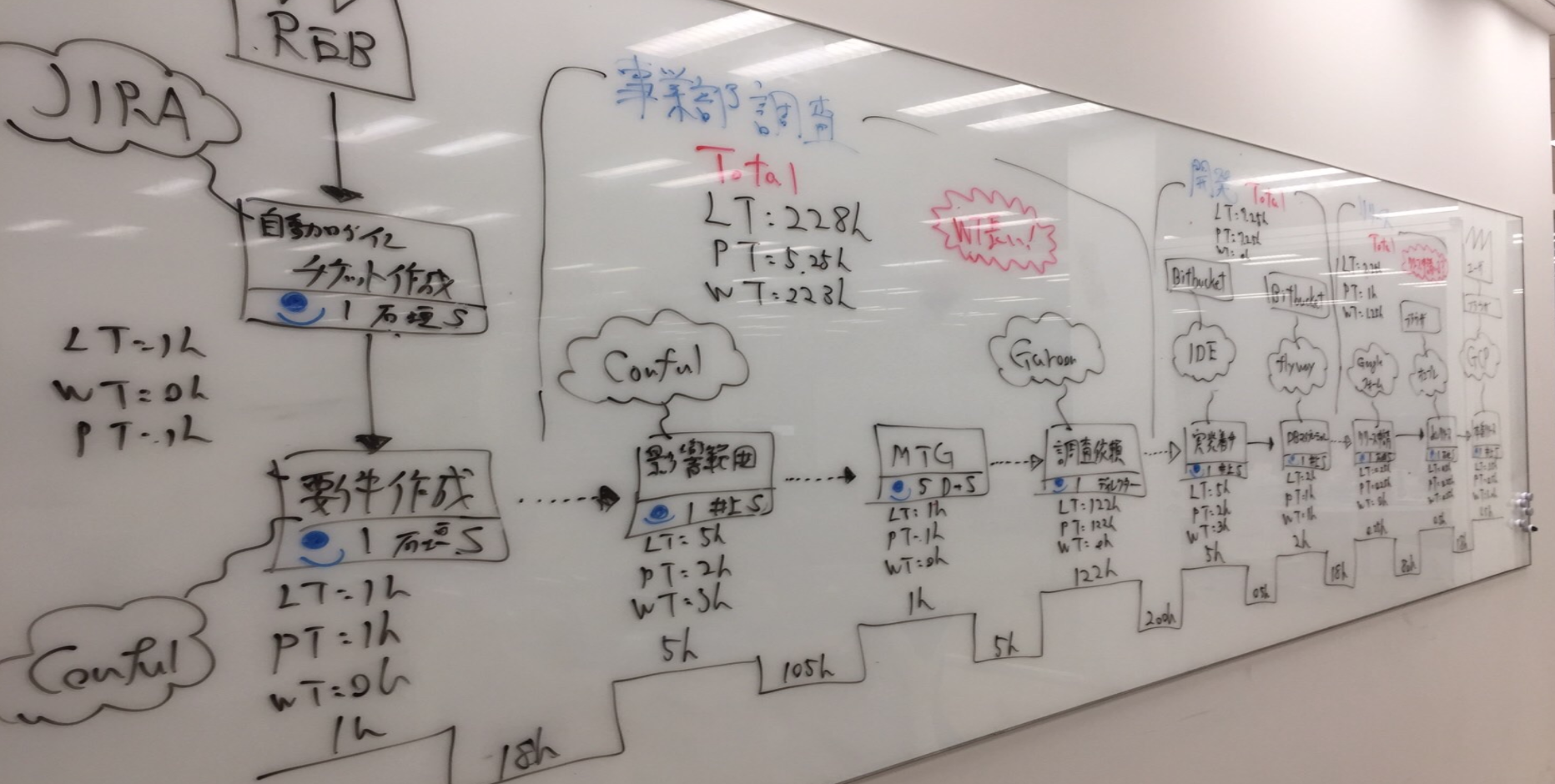
では、まず下記のような自チームが開発した機能をリリースするまでのVSMを書いたとします。
できれば、データを取るために複数のVSMを書くと良いです。
まず初めにやることは、
1. どこを改善するべきかカテゴリー分けすることです。
自チームですと下記の方になりました。

2. どのカテゴリーにリードタイムがかかっているか計算
1例ですが、総リードタイムが268.5hに対して下記の比率になりました。
ポイントとして上げるのであれば、ほぼすべてのVSMがこの比率になりました。
よくよく考えるとチームの行動パターン(開発プロセス)は一緒のことが多いためです。 この時点で「開発効率」をあげてもムダだと判断できた。 つまり、リリースまでに時間がかかっているからといって、開発者を増やせばよいというのは当てはまりません。
3. 改善ポイントを定める
可視化したら、改善するべきポイントを定めます。下記ですと
- ステークホルダーとの調整
- リリース準備 + 作業
が該当します。

4. Let's 改善
あとは、Let's 改善していくのみです。ここのどう改善していくのかは各々の開発者やステークホルダーが議論して対策を練っていきます。 ちなみに表題にもあるとおり、自チームでは ・ステークホルダーとの調整は、不要なMTGをなくした。 ・リリース準備+作業に関しては、CIを整備しリリース作業者の拘束時間を1m(oneClickでリリースできるように)まで短縮できました。 上記の2つの改善で約200時間の短縮につながりました。
最後の改善のポイントをあげます

まず、現状のVSM(ムダがある)を作成したら、必ず「未来のVSM」つまり「理想の開発プロセス」を記載したVSMを作成してください。 そのリードタイムの差分をとって、改善プロセスのphaseで改善していってください。
以上です。