Slack駆動を活かしたMonitoringについて
www.slideshare.net
上記スライドで説明しているSlackを活かしたSystemMonitoringについて記載します。 テーマとしては下記になります。
- Monitoringについて
- Slackを使ったDevopsの部分について
■ ブラックボックスモニタリングとホワイトボックスモニタについて
はじめにシステムのMonitoringには2種類あると思っています。
- ブラックボックスモニタリング
- ホワイトボックスモニタリング
の2つです。
ブラックボックスモニタリングとは、あるシステムを外部(例:ユーザ)からの動作、振る舞い、インターフェースの状態を見ます。
ホワイトボックスモニタリングとは、あるシステムの内部の状態を見ます。いわゆるコンピュータリソースです。
この2つがあることを認識して効果的にモニタリングをするべきと考えます。

そしてこの2つのモニタリングの中でどっちを優先するかについては、「 ブラックボックスモニタリング」を重要視するべきと考えます。 それは、サービスを運用する上でユーザに影響があるかないかが一番重要なためです。
■ モニタリングツールについて
上記でモニタリングには、ブラックボックスとホワイトボックスの2種類のモニタリング手法があるといいましたがここではそれぞれどういったモニタリングツールが有効かを記載します。
ブラックボックスモニタリングツールについて
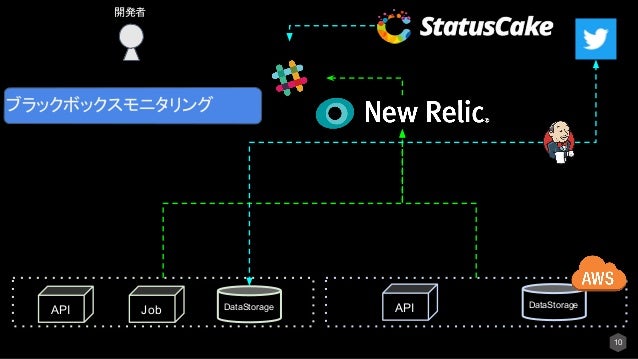
※図はAPIをモニタリングしている例です。
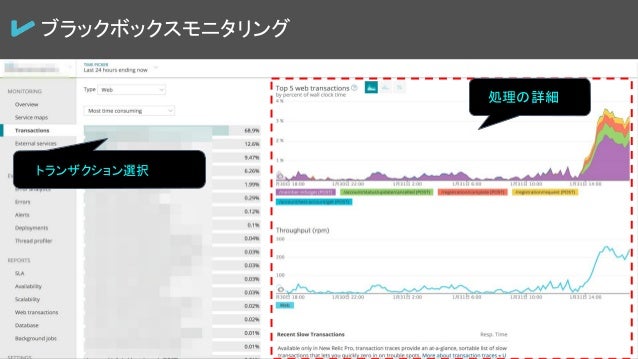
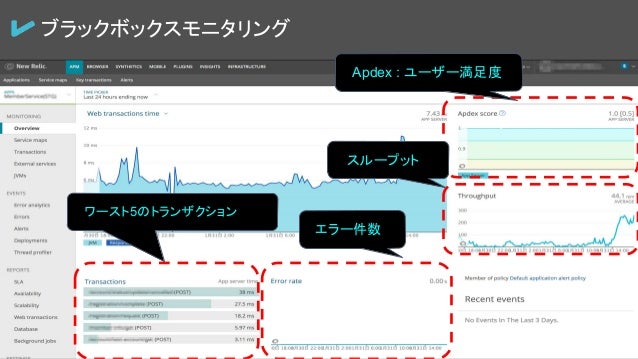
モニタリングツール① NewRelic APM
NewRelicは優れたモニタリングツールであり様々なサービス監視のノウハウを持っています。

今回、採用しているにはAPIのApplicationMetricsである、NewRelic APMです。
トランザクションのごとにスループットやエラー件数などを出してくれます。
モニタリングツール② StatusCake
StatusCakeはいわゆる死活監視の役割をしています。特定のURLに対して数分感覚でリクエストを送り続けサイトがダウンしているかどうかを監視できます。
モニタリングツール③ Twitter
再度にTwitterになります。こちらは精度的にはそこまで高くはありませんが、[サービス名] [できない] などの検索で引っかかったものに関してStatusCakeでURL監視を即時に飛ばしアラートを飛ばすなどをしています。ここらへんは機械学習などを置きこんで作り上げればもう少しよい精度のものができるかもしれません。
ホワイトボックスモニタリングツールについて
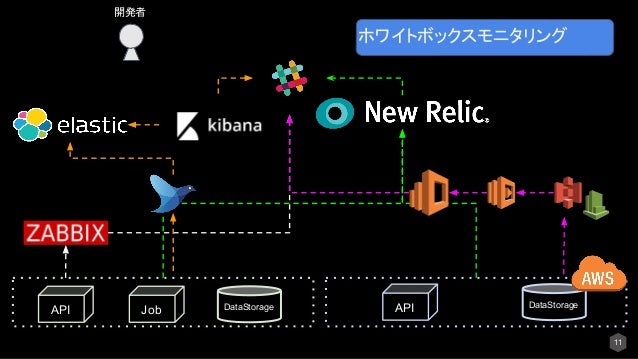
モニタリングツール④ Zabbix CloudWatch(AWS) NewRelic Infrastructure https://aws.amazon.com/jp/cloudwatch/ https://www.zabbix.com/jp/ https://newrelic.com
上記であげたものは、すべてコンピュータリソースの監視で利用しています。詳しい説明は省きます。
モニタリングツール⑤ Elastic https://www.elastic.co/jp/products/elasticsearch
最後にログ収集基盤に関しては、Elasticサービスが有名です。 自チームではログコレクタとして、fluentdを採用しElasticSearchに転送→kibanaでビジュアライズして可視化しています。 実際のサーバに入らなくても、エラーログなどの情報がGUI上で誰でも見れることはとても重要です。
■ Slack駆動について
最後にSystemMonitoringの運用(Devops)について記載します。
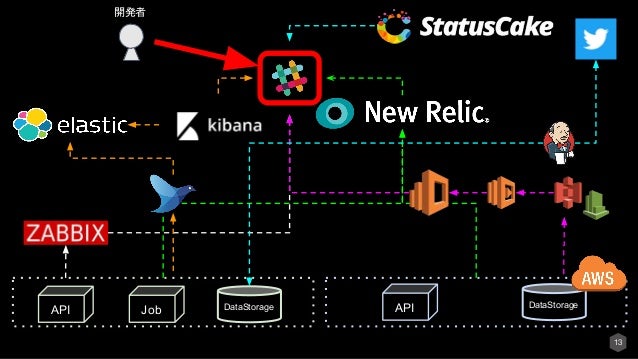
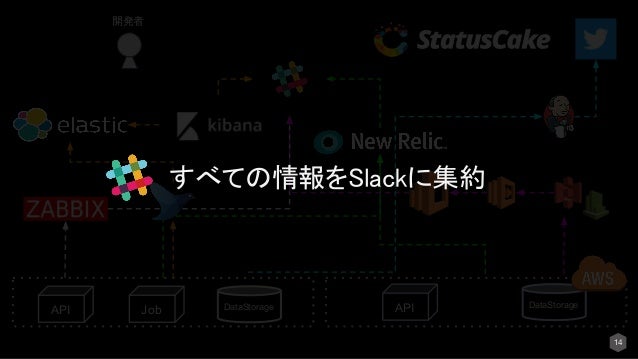
上記で説明したような多数のモニタリングツールを利用しているとその場面ごとに開発者がツールにアクセスするのは大変です。
なので図のあるようにSlackに集約します。
すると開発者が情報を取りに行かなくても、通知してくれるのでインシデントの観点からとても有効です。
※下記がインシデントの観点から実際にあった効果です。

また、通知だけでなく例えば検知したタイミングでプロダクトをロールバックしたい等があればそれもプロダクトとSlackをつなげてしまえばSlack上から障害対応も可能になっていきます。同様にモニタリングツールとSlackをつなげてしまえばとても幅は広がります。
■ まとめ
Monitoringについて
- ブラックボックスモニタリングとホワイトボックスモニタリングがある。
Slackを使ったDevopsの部分について
- モニタリングツール、プロダクトのinputとoutputをSlackにつなげることでインシデント管理、障害対応はとてもスピーディーに有効に働く。